.webp)
A customer files a warranty claim and attaches three things: a phone photo of a crumpled till receipt, a PDF invoice from a marketplace order, and a picture of a box label with a serial number half rubbed off. None of it is typed into a form. All of it has to be read, checked, and matched to an order before anyone can decide the claim.
The common assumption is that reading those files is OCR. Scan the image, get the text, done. That assumption is wrong, and it is why so many claim teams still key this data by hand.
OCR turns pixels into characters. It does not know that the string on line 14 is the purchase date, that the number near the barcode is the serial, or that the total at the bottom proves the item is in warranty. Closing that gap is the job of Claimlane's AI Agent, the first AI agent purpose-built for warranty claims and returns, which reads the documents, understands the fields, and checks them against the order.
Document extraction is not OCR, and the difference is the whole point
OCR is a 50-year-old technology that reads text off an image. It is a piece of the puzzle, not the puzzle. A receipt run through plain OCR gives a wall of characters with no idea which line is the date and which is the store address.
Extraction adds meaning. It identifies the purchase date, the retailer, the product, the price, and the order number, then knows that those fields together answer one question: is this claim covered. That understanding is what separates a scanner from something useful at claim intake, and it is the same logic that powers good warranty claims processing rather than slowing it down.
What AI claim document extraction actually does
At intake, the AI looks at every file the customer uploaded and pulls the fields that matter. From a receipt or invoice it reads the date, retailer, product, and amount. From a label or the product itself it reads the serial number. From the order data it confirms the buyer and the purchase channel.
Then it does the part OCR never could: it checks those fields against each other and against the brand's records. Does the serial match a sold unit. Is the purchase date inside the warranty window. Does the order number tie to a real order. This is the front door of any proof of purchase check, and it feeds straight into the rest of AI RMA automation. It works alongside, not instead of, image recognition for the defect itself, since one reads the paperwork and the other reads the damage.
The four documents every warranty claim hides
Most claims carry the same four pieces of evidence, and each one is a separate reading problem.
Pulling these cleanly is the difference between a claim that routes itself and one that lands in a queue for manual sorting. It is also the data backbone behind reliable serial number tracking and clean warranty claim forms.
Why warranty is harder than invoice extraction
Accounts-payable tools extract invoices all day, so brands assume warranty claims are the same job. They are not, and underestimating the difference is why generic tools disappoint here.
Supplier invoices are structured and consistent. Warranty evidence is whatever the customer happened to photograph: a faded receipt, a screenshot of an email, a marketplace order in a foreign layout, a serial label at an angle in bad light. The formats are unpredictable, and a wrong read has consequences, since approving an out-of-warranty claim or rejecting a valid one both cost money. That is why this sits inside the work of a purpose-built warranty claim software rather than a horizontal document reader, and why ecommerce AI agents built for the post-purchase moment behave differently from a generic extractor.
What manual claim data entry really costs
The hidden cost here is time, and time on a claim is a finance number once a team scales.
An agent reading a receipt, finding the serial, checking the order, and keying it all into the claim record spends a few minutes per claim before any decision is made. Call it four to six minutes. At 2,000 claims a month that is roughly 130 to 200 hours of pure data entry, most of a full-time role, spent transcribing instead of resolving. Pull that out and the same team absorbs more volume without hiring against it, which is the practical promise behind contact center automation.
The guardrails that keep extraction honest
Automating the read does not mean trusting it blindly. A document the model cannot read well is exactly where automation should slow down, not speed up.
Four controls keep it safe. A confidence score on each extracted field, so a low-confidence serial or date gets flagged. A human-in-the-loop step where any uncertain read routes to an agent with the original image attached. Configurable rules that decide which fields must always be confirmed by a person. And an audit trail recording what the model read, what score it gave, and what a human changed. With those, extraction is a fast assistant that still answers to people, the same principle behind responsible AI claims assistance.
How Claimlane's AI Agent reads and verifies claim documents
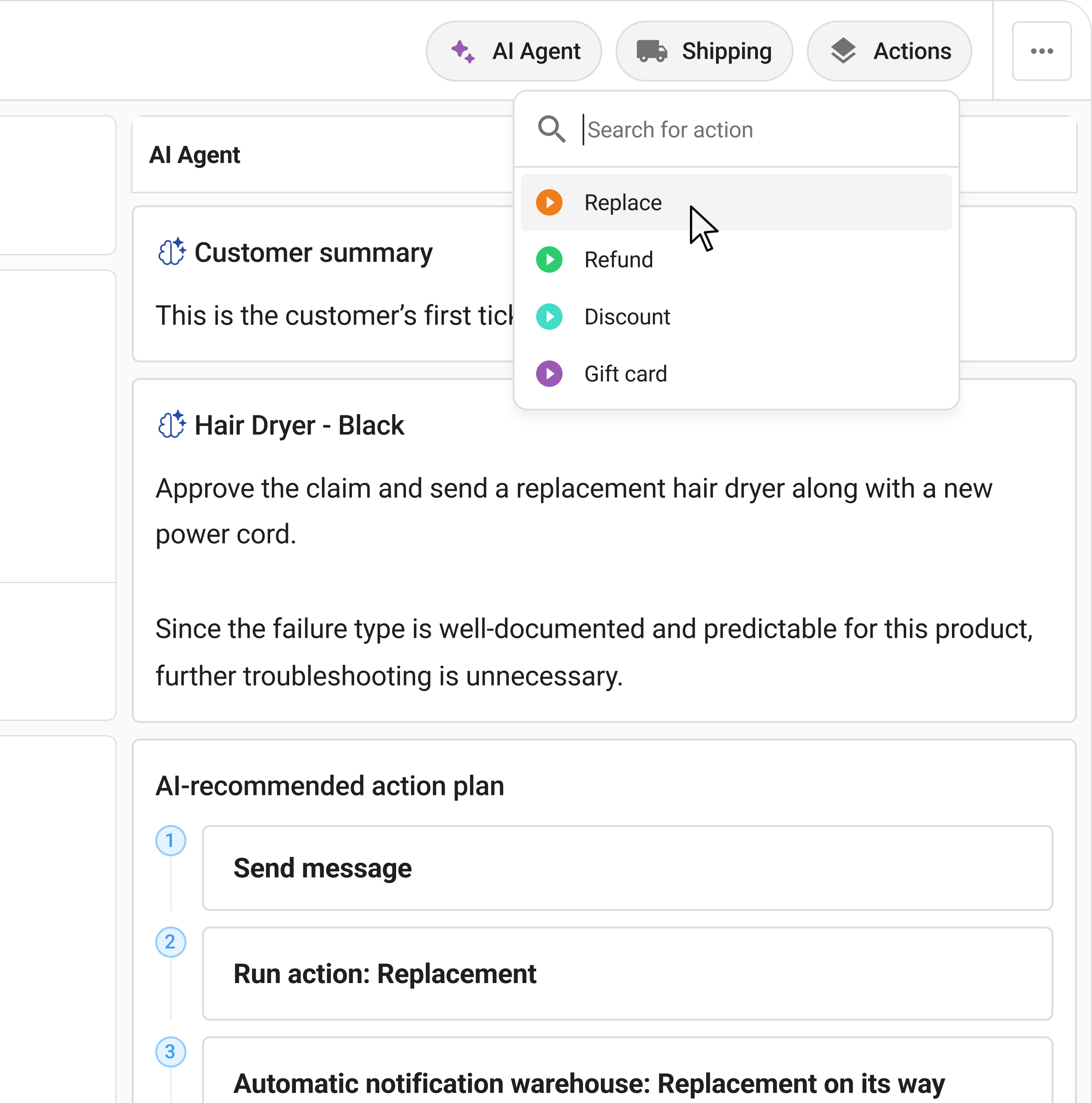
Claimlane runs extraction as part of intake, not as a bolt-on. When a customer submits a claim through the portal, the AI Agent reads the uploaded receipt, invoice, serial label, and order data, pulls the fields, and scores each one.
It then checks the read against the warranty rules for that product and supplier and against the order record, so the claim arrives already categorised and either ready to resolve or flagged for review. The agent reviews the documents the way it reviews defect images, applying the brand's rules rather than its own judgment. Customers submit everything through a self-service claims portal, and where a fault traces to a supplier, the structured evidence is ready to push through forward to supplier as a documented credit claim instead of a lost cost.
Connecting extracted data to the finance and helpdesk stack
Extraction only pays off if the clean data lands where the rest of the business works. A serial and a purchase date trapped in a claims tool help no one downstream.
Because the extracted fields are structured, they flow into the systems a brand already runs. Order and finance data reconcile against ERP systems like NetSuite, Microsoft Dynamics, and Business Central. Commerce data ties back to Shopify or the marketplace the order came from. And when a claim needs a human, the case and its read fields pass to a helpdesk like Zendesk or Gorgias with the work already done. This is also where it pays to be clear on fit. Simple size-and-fit returns on a Shopify store are well served by general returns apps like Loop or AfterShip, which do not need to read a serial number. Complex warranty claims that turn on proof of purchase, serials, and supplier rules sit with Claimlane. The same data feeds product warranty registration, so a registered unit already carries the proof a later claim needs.
.webp)